

OCR Production Nightmares
17 March 2013
Over on Twitter @LeeHazelwood with some comments by @TomMcCluskey were discussing the problems of OCR and eliminating irritating page headers and footers. This is a problem we have constantly faced since the beginning of digital content time. Plus a zillion other problems w.r.t. OCR. It is time to share the pain.
Over on Twitter @LeeHazelwood with some comments by @TomMcCluskey were discussing the problems of OCR and eliminating irritating page headers and footers. This is a problem we have constantly faced since the beginning of digital content time. Plus a zillion other problems w.r.t. OCR. It is time to share the pain.
I think this article and those to follow on this subject will be just too detailed for 99.99% of the 2013 digital content world to follow. However the high-accuracy OCR problems discussed are all as true today as they were 15 years ago.
There is still a lot of hard-copy content that deserves to be in digital content format so we are dumping 15 years of experience and solutions right here and in subsequent posts. But be warned our approach is very ISO 9000'y so it isn't a quick hack answer.
It is a pleasure in this post to share the extreme pain that is OCR digitization, production, failure and evolution.
Disclosure
In full disclosure Infogrid Pacific is a high-volume, high-capacity solution driven operation that does awesome things with really old and really new content. We work in the semi-slo-mo, hyper-zing-zone combo areas of digital content.
That means obscure Jawi manuscripts no-one has read for 500 years, impossibly rare Chinese documents that Ho Chi Minh scribbled in his spare time, 800 year old palm leaf manuscripts on how to cure warts and infertility, 10's of thousands of academic books, thousands of textbooks and thousands of trade books on everything from fantasy to food in many of languages.
The OCR Problem
Brilliant OCR technology sucks! No matter how good it is claimed to be, the quirks of typography and fonts laugh-at and make amazing OCR technology look mediocre. Perhaps you have to see tens of thousands of pages across thousands of books to really understand the murkiness of OCR technology. However given the analogue world problem it is solving it is probably as good as it will get.
When the minimum proofing quality standard is 99.995% (5 defects per 100,000 characters) there is not a lot of room for error. Depending on a lot of things OCR native accuracy can be from 95% to 99.9% (OCR manufacturers will claim 99.99% when the the Moon is in the seventh house and Jupiter aligns with Mars). Still miles away from the required minimum quality measurement (and even that has conditions).
The characteristics of fonts, quality of scanning, quality of typesetting all contribute to the accuracy of OCR output. In our production systems we will never put an image to OCR less than 600 dpi which has been scanned geometrically accurately without rotation. Rotation can introduce (barely discernible) disruptions in text lines in the middle of a page. The rule is OCR never gets better than the quality of the inputs.
There are always exceptions
From time-to-time clients say we can provide scans and they are really good. We generally accept them. They are inevitably 300dpi JPG scans with gutter distortion and all sorts of left-right page rotation problems. These types of inputs can increase OCR defects tremendously. JPG noise especially can have a catastrophic effect, particularly on diacritics and punctuation, but also other letters. Bad scans increase costs.
Our Problem
In 2000, with an OCR and proofing department of 500+ innocent young proofers feeding the tagging and format teams it was important to give them a chance to do good work and be proud of the output quality generated. A culture thing. No compromise.
In digital content production quality-speak everything is a value-addition process except proofing of OCR text, which is a defect-reduction process. That means having the tools for the job and automating what can and should be automated as long as any machine process doesn't introduce or miss defects.
Get the Inputs Right First
Many documents and books have regions that are not required in the output, or for some special reason need zone controls.
Not required content is headers and footers, perhaps images that contain extensive text, advertisements in magazines and similar. It's easier to identify content to be eliminated from a picture of the page than it is from a cloud of OCR'ed text.
Zone control OCR extraction examples are academic articles and magazines with columns, indexes, floated figures, tables and sidebars, self-help books with margin-notes and strange text layouts, images containing extensive text. Save hours by zoning the content to avoid an OCR content mash-up.
The IGP:OCR-CG Latin network linked desktop application allows the zoning of images before they go through OCR. The editor can put exclude lines for headers and footers, plus zone instructions for the assembly processor. This set of pixel accurate classification OCR Zones is then saved and used by the OCR post processor when creating the final output XHTML for proofing.
For a simple novel it is only a matter of setting the header and footer exclusion lines once and applying them to the whole document.
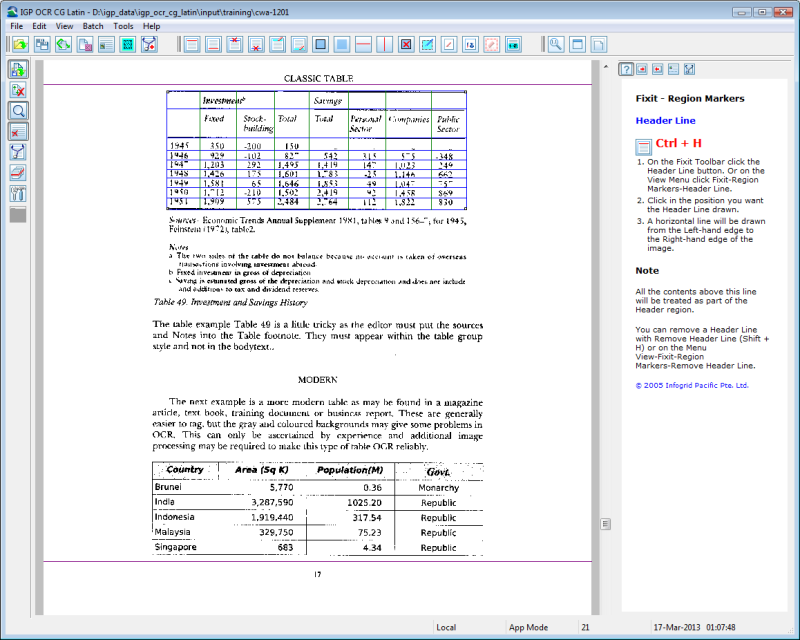
This is the IGP:OCR-CG Latin desktop application in FixIt mode showing region lines. The two horizontal purple lines are header and footer boundaries. Content above and below these will not come out in the final OCR'ed text. The blue region lines in the table ensures it can be assembled correctly into cells after OCR. These markers are stored as metrics and used to modify the XML area map.
The Area Map
OCR solutions give access to an X(H)ML document with the X Position, Y Position, Height, pixel layout metrics of every character, word and line plus font style, weight and family properties. The OCR Zone data from the markup process is used to clean out the headers and footers, move inserted blocks to the correct place, make sure tables come out extracted accurately and a lot more.
So that is how we ensure both simple and complex OCR content is exactly the content you need and that it comes out correctly every-time. It saves a lot of time and money getting things done in the right order.
We never use spelling-correction or spell checkers in proofing because they introduce more defects, and defects that are difficult to discover, than they fix.
Everyone's Problem - OCR Pattern Defects
Way back in 2000, Walter M, one of our best proofers corrected one of my quality performances (rants) by saying "Yes sir, but what about when rn become m".
Booom! Clouds parted, Angels sang. I was smart enough to say "go on". Walter gave me a whiteboard list from the top of his head of 100+ OCR character pattern recognition defects.
After a lot of programming this professional knowledge was encapsulated into our proofing tools. The OCR pattern defects are listed below for the world to love/hate and/or ignore. OCR can do nothing about them. We have to blame the Greeks and Romans for creating such stupid combinational characters in a pretty, but OCR unfriendly alphabet system.
The document characteristics that create OCR recognition pattern defects are:
- Random defects primarily due to page image blemishes (IE. Don't do lousy scans)
- Pattern defects where the combination of scan quality, typesetting method and font cause the OCR to misinterpret character patterns consistently. (Big serifs and no serifs are both enemies. Tight kerning another).
The miserable fact is that OCR pattern defects are image quality, font-family and typographic technique specific, and there are enough of them that shift meaning and create real words that spell-checkers can't find. This probably doesn't matter when you are manually proofing your single document, but when producing 15-20,000 plus pages per day to a QC/QA measured quality standard these defects are always ready to bite.
Getting Better at Getting Better
Most reasonable quality digital content production systems will use double proof and single compare to get to the 50 defects in a million character level. To go beyond this, and if you pay more there are double proof and triple compare methods as well.
There is an inherent flaw in these proofing systems in that they are labour heavy and rely on human observation. Doing that for eight-hours a day is of course mind-numbing.
In 2009 we decided it was time to come into the 21st Century. We spent a year developing IGP:Proof21 (an in-house tool). This tool uses a lot of very intensive algorithmic processing to check and test everything and work out what the proofer needs to inspect.
When the proofer makes corrections the application is constantly updating the document with the changes effectively reducing the number of operations as they move forward. It also adds these to a QC inspection list because the minimum quality statement is "If a person does something, another person must check it."
We now proof twice as many pages with half the proofers at higher quality.
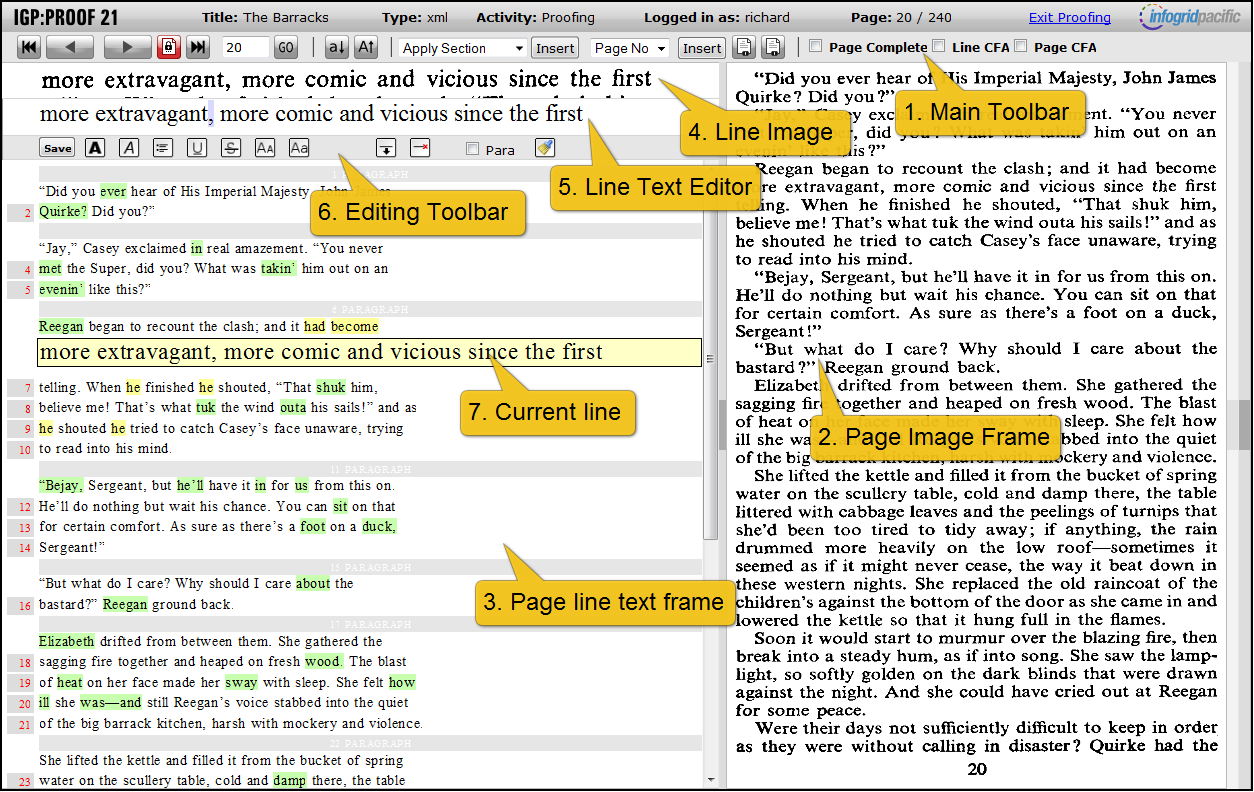
This is the main IGP:Proof21 interface. The proofer only has to inspect lines with warning highlights. At the top the current line image and text are shown next to each other.
If any organization tells you they are achieving some parts per million proofing quality statistic, ask to see their statistics and how they are calculated. Chances are there will be no quality statistics available at all. Quality systems measure change/improvement over time. When introducing tool and process changes in a critical process like proofing it can takes months to see the improvement (or otherwise).
Summary
Having employed and trained thousands of young people in the fine art of digital content production, and been on a journey that has created dozens of specialist content production tools, the OCR/proofing problem is without doubt the biggest challenge in the digital content production continuum.
The three axises of digital content production are quality, complexity and productivity. If the tools and approach address the first two, the third looks after itself. Cost reduction can only be an outcome of defect free production which addresses all levels of content complexity.
That's it for this weeks gripping episode on OCR and proofing. Below are the OCR pattern defects we handle in our proofing algorithms to discover which content is being made-up by the OCR and which is the real-deal. No spell-checking required.
Appendix: Common OCR Recognition Pattern Defects
Very Unsafe List
m ➝ in
m ➝ nn
m ➝ rn
rn ➝ m
d ➝ tl
d ➝ cl
d ➝ ci
n ➝ ri
u ➝ ii
ba ➝ ha
ha ➝ ba
Th ➝ di (with some fonts)
Very Unsafe Examples
in:m refrained reframed
nn:m timed tinned
rn:m corners comers, modern modem, stern stem
cl:d dash clash, day clay, dear clear, dip clip, dock clock
tl:d gentler gender, title tide, entitles entities
ci:d acids adds
ri:n carriage carnage, rioting noting, severity seventy, stories, stones
The die
General List
ab ➝ ah
ah ➝ ab
ac ➝ ae
ae ➝ ac
al ➝ ai
aq ➝ ag
ag ➝ aq
ay ➝ av
bb ➝ hh
bb ➝ hb
bc ➝ be
be ➝ hehe ➝ be
be ➝ bc
bi ➝ blbl ➝ bi
bo ➝ ho
ho ➝ bo
hu ➝ bu
ca ➝ ea
ea ➝ ca
ed ➝ cd
cf ➝ of
of ➝ cf
cl ➝ ci
ci ➝ d
cl ➝ dco ➝ ca
cr ➝ erer ➝ cr
cs ➝ es
es ➝ cs
db ➝ dh
di ➝ thth ➝ di
dl ➝ di
di ➝ dl
el ➝ ei
et ➝ el
fc ➝ fe
fc➝ fo
fl ➝ fi
fy ➝ ty
ty ➝fy
gl ➝gi
gu ➝qu
qu ➝gu
ia ➝la
la ➝ia
ie ➝ ic
ie ➝ le
ii ➝ ilii ➝ u
il ➝ ll
il ➝ ii
io ➝ lo
ld ➝ id
li ➝ ll
ll ➝ li
ll ➝ Il
lm ➝ im
lm ➝ Im
lv ➝ iv
lv ➝ Iv
or ➝ ur
or ➝ ür
et ➝ ot
pi ➝ pl
pl ➝ pi
ga ➝ qa
qo ➝ go
go ➝ qo
qs ➝ gs
qu ➝ guro ➝ ru
ru ➝ ro
sa ➝ se
tb ➝ thtt ➝ ff
ub ➝ uh
ue ➝ uc
vs ➝ us
wb ➝ whnn ➝ m
ri ➝ n
rl ➝ d
rn ➝ m
tl ➝ d
in ➝ m
m ➝ nn
m ➝ rn
d ➝ tl
d ➝ cl
d ➝ ci
n ➝ ri
u ➝ ii
a1 ➝ al
al ➝ a1
Unsafe Example
ai:al fail fall, hail hall, mail mall, tail tall, Waiter Walter
Case Defects
These are not as serious as pattern defects and normally occur on isolated numbers where the OCR does not have reference to a line of text for a height reference.
Ix ➝ ix
Iy ➝ ly
IV ➝ iv
IX ➝ ix
OO ➝ oo
O0 ➝ oo
xl ➝ xi
Xv ➝ xv
Xx ➝ xx
XI ➝ xi
XV ➝ xv
XX ➝ xx
Orphan character case confusion
The following characters could be upper or lower case when not surrounded by other characters. When the OCR has no other characters in a line to compare them with, it can transpose case. Usually lowercase becomes upper case.
c k o p s u v w x z
Close character look-alike confusion
With some fonts, especially sans serif fonts, zero and the character “O” , and the number “one” and characters “lowercase I”, “lowercase L” and sometimes “Uppercase I” can be confused.
0 ➝ O
0 ➝ o
i ➝ l ➝ 1
B ➝ 8
b ➝ 6
S ➝ 5
What causes OCR defects
Font size, Decoration, or Obscuring
OCRs fixed recognition limits based on point size
Font serif patterns
Font decoration and styles
Diacritics and strange diacritic combinations
Page disturbances
Too much document rotation
speckles on the image
Text layout
Proximity confusion
The number One disappears when close to a table vertical rule, especially if the font is sans-serif. Eg: |1
Start a real digital content strategy with
IGP:Digital Publisher
The complete digital publishing content management and production solution.
Available as for Small and Medium publisher:
IGP:Digital Publisher is also available as a full site license purchase.
Contact us for more information...
Use one master XHTML file to instantly create multiple print, e-book and Internet formats.